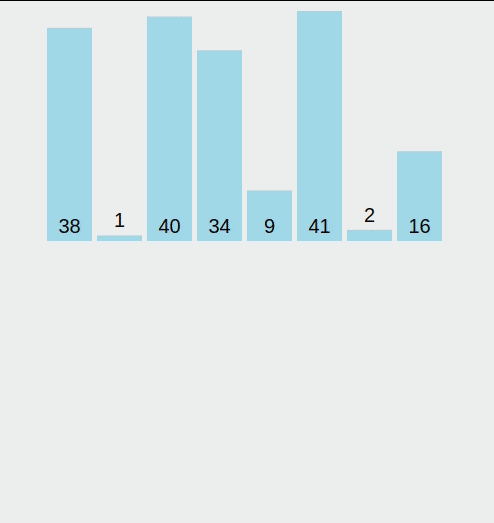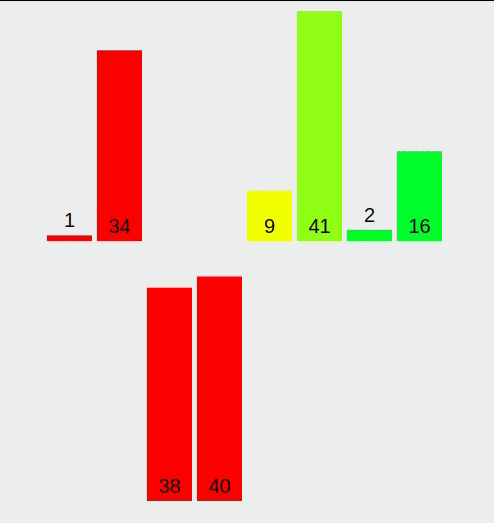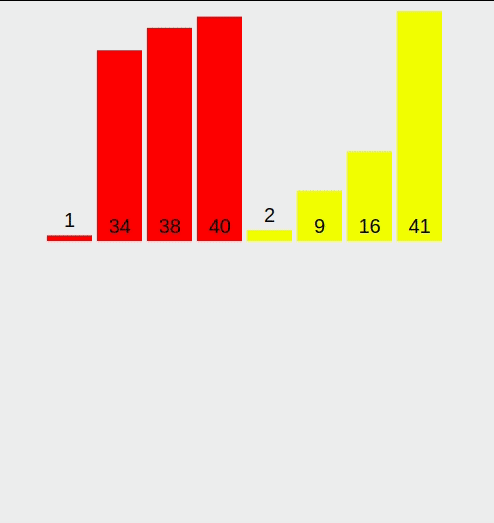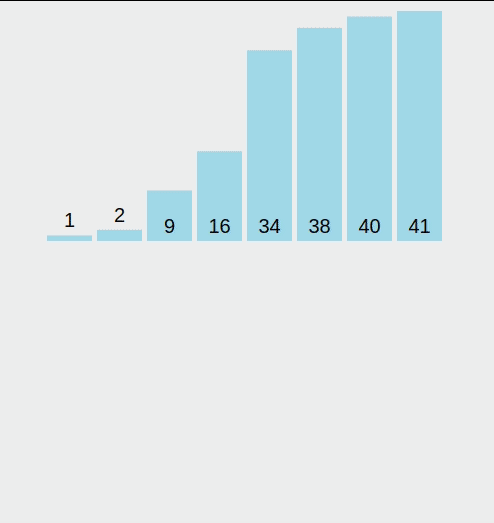
계수 정렬(Counting Sort) 계수 정렬(Counting Sort)은 값을 직접 비교하지 않고, 등장 횟수를 세는 방식으로 정렬을 수행하는 비비교 정렬 알고리즘입니다. 정수나 정수로 표현 가능한 데이터를 정렬할 때 매우 빠르며, 특히 데이터 값의 범위가 작고, 중복이 많을수록 효율적입니다.정렬하고자 하는 값들의 개수를 카운트 배열에 저장한 뒤, 각 값을 정렬된 위치로 바로 배치하는 방식이기 때문에 최악의 경우에도 O(n + k)의 시간 복잡도를 가집니다. (k는 값의 최대 범위)단점은 데이터 값이 음수이거나, 범위가 너무 넓을 경우 메모리 낭비가 발생할 수 있다는 점입니다. 1. 계수 정렬이란? 계수 정렬은 다음의 방식으로 정렬합니다.입력 배열의 값들을 세어, 값마다 등장 횟수를 저장누적 합을 ..